




A successful project is always the combination of technologies that are not just compatible, but that build upon each other’s strengths.
One of Atoti’s defining features is its capability to stream real-time updates and instantly re-compute aggregated views, but this capability is underutilized if data sources provide infrequent updates. When building a project with Atoti in mind, it is a good practice to think about the end-to-end data flow that will best meet our needs and take advantage of its strengths.
MongoDB is a distributed JSON document-based platform. It’s designed for near real-time operational data processing, particularly in the financial services industry. It offers flexibility, scalability, and resilience, which makes it a very good fit for Atoti where instant aggregation, allocation, and risk metric exploration across multiple dimensions are required.
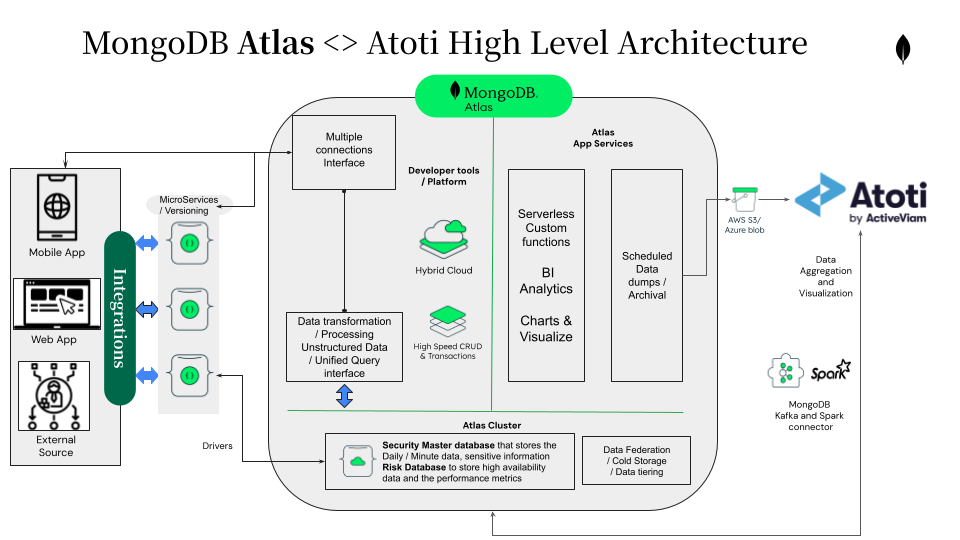
In this article, we’ll see how to combine MongoDB and Atoti to create a solution for real-time aggregation, exploration, and reporting of data, in the context of financial risk analysis.
We’ll connect MongoDB to Atoti, directly and via Kafka, to perform start-of-day loading and then set up MongoDB’s continuous data streams to be aggregated and consolidated in Atoti, alongside other real-time data like market prices, sensitivities and cash flows.
Data Flow Structure
The diagram below gives an outline of the integration stack we’ll create to perform the start-of-day loading of data and then provide continuous updates. We identify three different data streams, according to different pace and volumes of data loading
- Start of Day : This refers to the initial loading of the data at start of day, describing the portfolio open positions and transactions, the open balance sheet, associated risk measurements and current exercise profits and losses, etc..
- Intraday frequent updates: Frequent updates can involve uploading specific datasets (such as instrument-level prices and sensitivities, new positions, new cash flows and settlement, etc.) into Atoti at regular intervals using batches.
- Real-time: Between intraday updates, Atoti performs real-time analysis of prices, risk measures, and sensitivities such as polynomial interpolations and updated statistical measurements on price distributions and risk model surfaces by loading real time price updates as well as cash flow and transaction settlement confirmations.
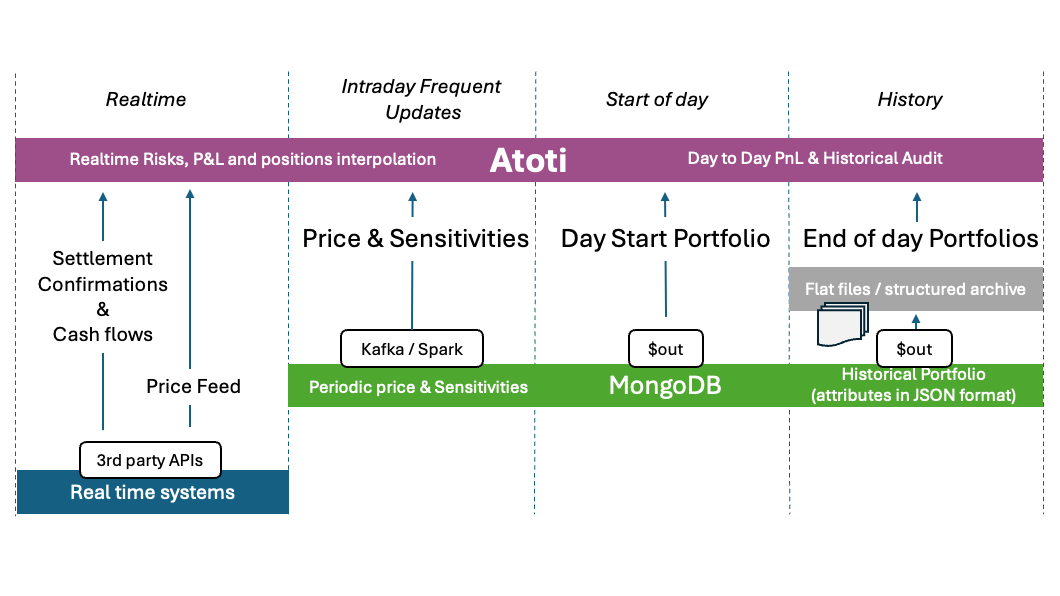
Atoti can make efficient use of 2 types of data output provided by MongoDB:
$outoperator: it allows Atoti to extract data batches to perform the initial data loading at the start of the day and more loadings at specific intervals throughout the day. You can customize the frequency, and it’s best-practice to spread the data over multiple nodes to achieve maximum performance and throughput.
- Real-time publication can be achieved using one of both paths: MongoDB Spark connector, Kafka connector.
Over Kafka or Spark, MongoDB publishes incremental updates of positions values and sensitivities, while market prices, cash flows and settlement confirmations are loaded in real time from third party operational systems
In this context, the incremental loading of position values and sensitivities can be achieved using either:
- Regular Intraday batch process where all sensitivities are recalculated in a frequent batch process, every N minutes.
- On demand Incremental loading where Atoti monitors market movements and triggers on-demand revaluation for instruments that have deviated away from the previous baseline.
In this guide, we will show how to create an optimized analytics platform, leveraging batch loading and real-time streaming depending on which mode is most relevant over the course of the day.
1- Initial start-of-day data loading
For start-of-day loading, Atoti can ingest batch files into one or many data nodes based on csv, parquet files or JDBC data access. To perform data load balancing and achieve a desired loading time, we divide the data across different hierarchies, such as one data node per reporting date, per desk, etc.
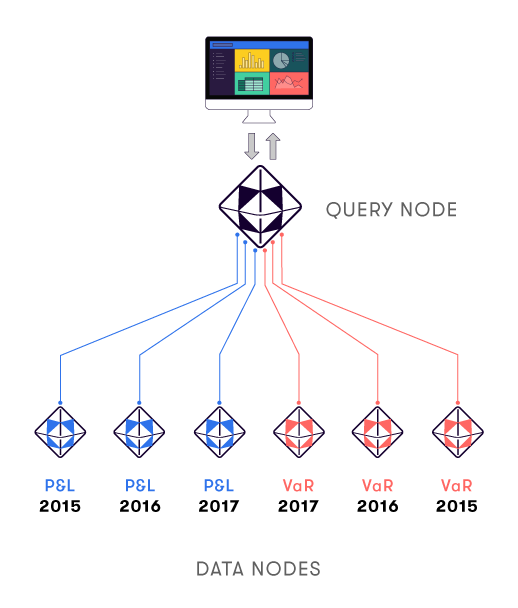
On each node of the cluster, we can run two kinds of cubes:
- Data nodes: it helps scale up the data loading time from the source systems by parallelizing data transfer. This allows the server initialization to complete faster.
- Query nodes: it helps scale up the data querying time, by parallelizing queries according to the scope of data they address.
Atoti data source API enables us to populate the Atoti datastore(s) from multiple data sources. Currently, Atoti supports the following data source types:
We also support other formats, which can be addressed on a case-by-case basis. Get in touch with partners@activeviam.com to learn more!
On the MongoDB side, this is how we can extract the required data.
Batch end-of-day data exports using $out : To use the $out operator in MongoDB, you can include it as the last stage in an aggregation pipeline. The $out operator writes the documents returned by the pipeline to a specified collection, object storage (only in MongoDB Atlas) or file system in csv | json | parquet format . Here are the different ways you can use the $out operator:
- Specify only the output collection:
{ $out: "<output-collection>" } - Specify the output database and collection:
{ $out: { db: "<output-db>", coll: "<output-collection>" } } - Output to a time series collection (available in MongoDB 7.0.3 and 7.1):
{ $out: { db: "<output-db>", coll: "<output-collection>", timeseries: { timeField: "<field-name>", metaField: "<field-name>", granularity: "seconds" || "minutes" || "hours", } } }
This will output the documents to a time series collection with the specified time field, meta field, and granularity. - For writing data directly into object storage we must setup:
- A federated database instance configured for an S3/Azure Blob bucket with read and write permissions
- A MongoDB user with the atlasAdmin role or a custom role with the
outToS3privilege.
We can use the following syntax to write to S3
{ "$out": { "s3": { "bucket": "<bucket-name>", "region": "<aws-region>", "filename": "<file-name>", "format": { "name": "<file-format>", "maxFileSize": "<file-size>", "maxRowGroupSize": "<row-group-size>", "columnCompression": "<compression-type>" }, "errorMode": "stop"|"continue" } } }
We can use the following syntax to write to Azure Blob
{ "$out": { "azure": { "serviceURL": "<storage-account-url>", "containerName": "<container-name>", "region": "<azure-region>", "filename": "<file-name>", "format": { "name": "<file-format>", "maxFileSize": "<file-size>", "maxRowGroupSize": "<row-group-size>", "columnCompression": "<compression-type>" }, "errorMode": "stop"|"continue" } } }
for more detail on how to achieve this follow docs in link
-
Remember that if the collection specified by the
$outoperation already exists, it will be replaced with the new results collection upon completion of the aggregation.
2 – Real-time data update & Intraday frequent updates
Both incremental and real-time publication can be provided by MongoDB through standard Spark or Kafka connectors. ActiveViam has developed best practices in integrating these streams with Atoti. We can see an example in the Atoti Notebook Gallery in this notebook:
Real time risk as explained in the following articles:
On the MongoDB side, this is how such data may be extracted.
On Spark and Kafka data interfaces for Atlas Spark Connector for MongoDB
The MongoDB Connector for Apache Spark can take advantage of MongoDB’s aggregation pipeline and rich secondary indexes to extract, filter, and process only the data it needs – for example, analyzing all customers located in a specific geography.
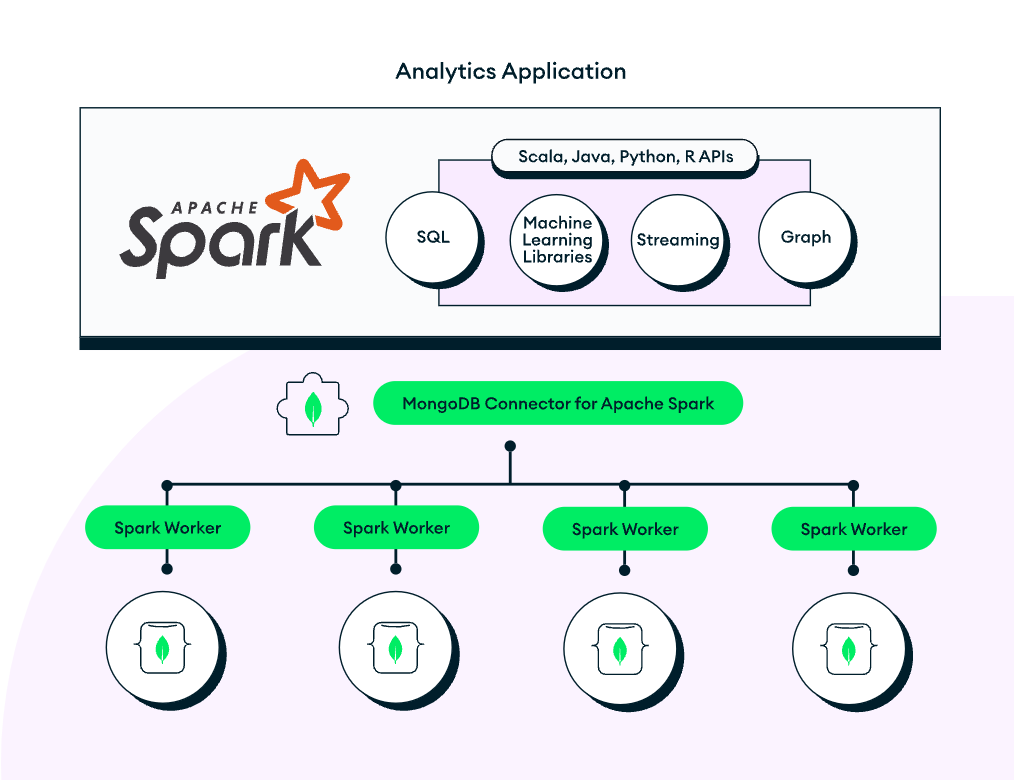
With the Connector, we have access to all Spark libraries: dataset for analysis with SQL (benefiting from automatic schema inference), streaming, machine learning, and graph APIs. We can also use the Connector with the Spark Shell. By doing so, we can use the Spark connector to pull in only the necessary materialized views of data during real-time processing.
Here is an example snippet of how to use Spark connector in a Jupyter notebook using pyspark.
# Initialize the MongoDB connection string, database we are using in the notebook.
from pyspark.sql import functions as F
from pyspark.sql.window import Window
from datetime import timedelta
'''
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.13</artifactId>
<version>10.3.0</version>
</dependency>
'''
MONGO_CONN = "<your_mongodb_connection_string>"
# Default sample dataset available through MongoDB Atlas.
database = "sample_analytics"
rdf=spark.read.format("mongodb").\
option('spark.mongodb.connection.uri', MONGO_CONN).\
option('spark.mongodb.database', "sample_restaurants").\
option('spark.mongodb.collection', "restaurants").\
option("spark.mongodb.partitioner","com.mongodb.spark.sql.connector.read.partitioner.SamplePartitioner").\
option("spark.mongodb.read.partitioner.options.partition.field", "restaurant_id").\
option("spark.mongodb.read.partitioner.options.partition.size",1).\
option('spark.mongodb.aggregation.pipeline',[{"$project":{"_id":0}]).load()The documentation on how to configure the Spark connector to load and write data is available on MongoDB’s website:
- Batch Read Configuration Options
- Batch Write Configuration Options
- Streaming Read Configuration Options
- Streaming Write Configuration Options
The batch load and write process supports data partitioning, allowing larger volumes of data to be processed simultaneously.
In Streaming mode, the Spark connector uses MongoDB’s change streams to pull data, reducing the required throughput for handling the same transaction volume.
The MongoDB-Spark connector is free and available on Spark packages, the community index for third-party Apache Spark packages. For even higher streaming throughput, Apache Kafka can be configured as a source or sink connector for MongoDB collections, enabling faster data movement for stream processing.
Kafka Connector for MongoDB
The MongoDB Kafka Connector is a Confluent-verified connector that allows the persistence of data from Apache Kafka topics into MongoDB as a data sink, and publish changes from MongoDB into Kafka topics as a data source.
This connector provides a seamless integration between Kafka and MongoDB, allowing for easy transfer of data between the two systems.
We can use the MongoDB Kafka Connector with one of the following MongoDB partner service offerings to host the Apache Kafka cluster and MongoDB Kafka Connector:
- Self Managed: it offers connector jars for MongoDB Source and MongoDB Sink Connectors here.
- Confluent Cloud: it offers the MongoDB Source Connector and the MongoDB Sink Connector.
- Amazon Managed Streaming for Apache Kafka (MSK)
- RedPanda Cloud: it offers the MongoDB Source Connector and the MongoDB Sink Connector.
Additionally, we can use Atlas Stream Processing, a MongoDB-native way to process streaming data using the MongoDB Query API. It allows us to continuously process streaming data, validate schemas, and materialized views into either Atlas database collections or Apache Kafka topics.


