80/20 data science dilemma: tough working on Twitter sentiment
When my manager brought up the idea of forecasting Cryptocurrencies’ returns with Twitter sentiment, I immediately performed a Google search on how I can lay my hands on the tweets and the cryptocurrencies. Information seems to be abundant and readily available on how I could gather the data. But that’s where I was wrong…
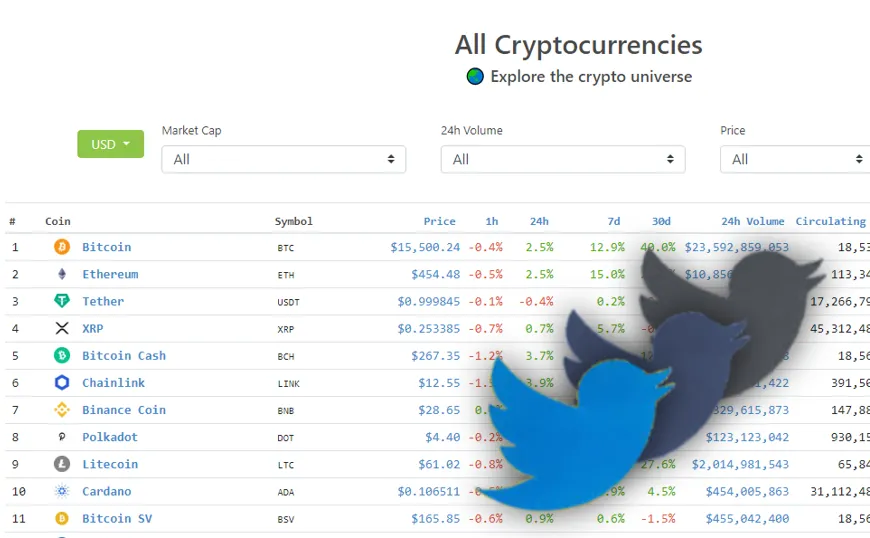
Caption: Screen grab from CoinGecko.com
I may be wrong but most articles I found online showed how to scrape Tweets but not how we can bulk scrape them. Also the sheer amount of unconforming data that is available with the platform can come with a hefty price tag. Not to mention the amount of clean up that comes after. This article addressed the difficulties that I faced while trying to obtain the Twitter sentiments for different cryptocurrencies. I hope this helps those who are looking at working with Tweets. Feel free to add on to the list.
Let’s quickly go through some of the alternative solutions before we talk about Tweepy, the Python library for accessing the Twitter API.
Alternatives – Open-source libraries
There are open-source libraries such as GetOldTweets3, snscrape, TWINT etc. GetOldTweets3 for instance, mimics the search scrolling of Twitter search on browsers. However, when Twitter decided to remove the “/i/search/timeline” endpoint, developers scrambled to find fixes to continue scraping the Tweets ( T~T ) Also, depending on your use of the data, be sure to check that you didn’t breach any of Twitter’s policy.
Paid services
There are paid services such as trackmyhashtag and TweetBinder which either limits the download by the number of hashtags and/or the number of tweets by the amount that is paid. For instance, with TweetBinder, you can get approximately 140,000 tweets for slightly more than $200 USD.
Tweepy
Instead of paying others, we can use the standard search API or data streaming to obtain a sampling of Tweets published in the past 7 days. However, since it is a sample of data, we cannot be sure about the completeness of the data we have even if we overcome the rate limit imposed by the API (v1.1).

Caption: All request windows are 15 minutes in length
While I’m ready to pay for the premium Premium Search Tweets: Full-archive endpoint which provides complete and instant access to all Tweets, it became a costly lesson for me.
We can try out the premium API by creating a sandbox environment. Below are the differences between the free Sandbox and the paid Premium feature:

IT IS VERY IMPORTANT to try it out with the sandbox to be sure that your script is doing exactly what you want before you start using your paid feature.
Note that for the premium feature, per data request allows up to 500 tweets and we can have 60 requests per minute, we can download 1,800,000 tweets in an hour. Sounds amazing right? That’s until we see the price plan.
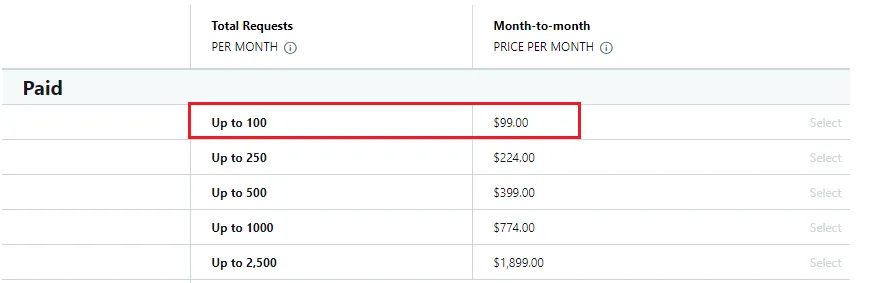
For $99 USD, we could have up to 100 requests and that means that we would have exhausted our requests in less than 2 minutes! That also translates to 50k data which is not a lot – at least I wasn’t able to download 2 days of cryptocurrency tweets. A month’s worth of data potentially can go up to $1.5k USD. Ouch! My wallet hurts… and imagine any mistake that you made in the coding such as entering the wrong search key or not maximizing the max_results to the limit of 500 tweets (-‸ლ), in my case, there’s only less than 2 minutes to react before the quota is exhausted and $99 goes down the drain. Can you not hate Twitter (or blame it on our own inexperience maybe)?
Last Option…
I haven’t explored the below. If you have, I would love to hear about your experience.

Lessons learned with Tweepy
1. You need a Twitter developer account in order to work with Tweepy.
Be prepared to be asked questions about how the data will be used before the account gets approved. Check out this article on how to apply for the account. I haven’t received the approval for the first account I applied for but the second account I tried was approved immediately. I still don’t quite understand (҂◡̀_◡́)ᕤ
2. Authorization
Create an App and get the access tokens for the API. You can access the API key and API key secret as shown below:
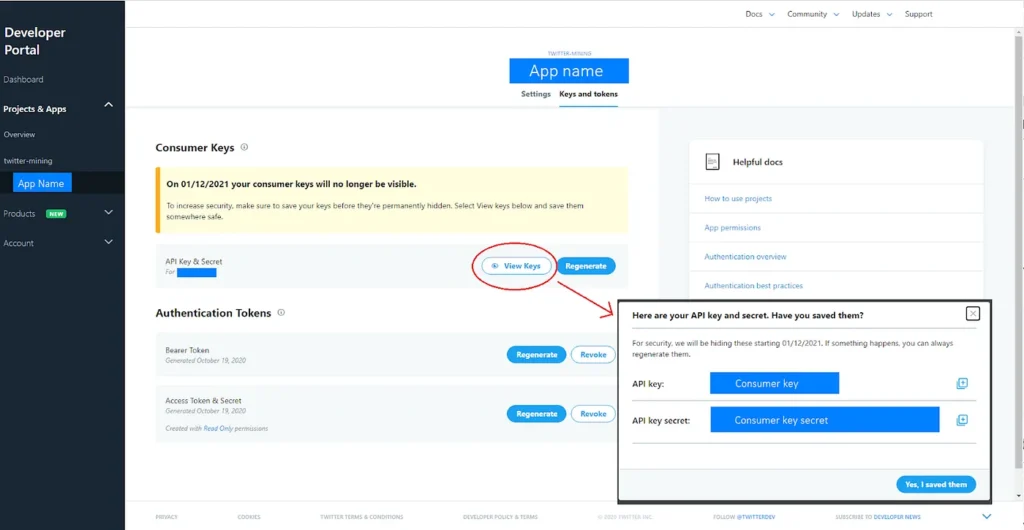
These are your consumer key and your consumer secret. Since I’m only downloading the tweets in this case and don’t require any callbacks, I have no use for the access token and secret. You can refer to the documentation if you have such needs.
twitter_keys = {
"consumer_key": "<To be replace>",
"consumer_secret": "<To be replace>",
}
# tweepy library to authenticate our API keys
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
api = tweepy.API(auth)3. Overcoming rate limit reached exception
To prevent your script from terminating upon hitting the rate limit, set the wait_on_rate_limit to True. This way, your script will wait until the 15 minutes window is over before resuming again.
api = tweepy.API(
auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True
)4. Start mining data
I unintentionally lost my dataframes a couple of times due to an unexpected exception or restart of kernels. Hence, I prefer to output the data periodically so that I do not have to restart from ground zero.
def mine_crypto_currency_tweets(self, query="BTC"):
last_tweet_id = False
page_num = 1
data = get_df()
cypto_query = f"#{query}"
print(" ===== ", query, cypto_query)
for page in tweepy.Cursor(
self.api.search,
q=cypto_query,
lang="en",
tweet_mode="extended",
count=200,
).pages():
print(" ...... new page", page_num)
page_num += 1
for item in page:
mined = {
"tweet_id": item.id,
"name": item.user.name,
"screen_name": item.user.screen_name,
"retweet_count": item.retweet_count,
"text": item.full_text,
"mined_at": datetime.datetime.now(),
"created_at": item.created_at,
"favourite_count": item.favorite_count,
"hashtags": item.entities["hashtags"],
"status_count": item.user.statuses_count,
"followers_count": item.user.followers_count,
"location": item.place,
"source_device": item.source,
}
try:
mined["retweet_text"] = item.retweeted_status.full_text
except:
mined["retweet_text"] = "None"
last_tweet_id = item.id
data = data.append(mined, ignore_index=True)
if page_num % 180 == 0:
date_label = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
print("....... outputting to csv", page_num, len(data))
data.to_csv(f"{query}_{page_num}_{date_label}.csv", index=False)
print(" ..... resetting df")
data = get_df()
date_label = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
data.to_csv(f"{query}_{page_num}_{date_label}.csv", index=False)
In the above code snippet, I am using the coin symbols as my search hashtags. I must have great faith in the public to tag their Tweets to the correct hashtags! E.g. for #BNB, I can get tweets such as the following which is more for bed and breakfast:
Enjoy Fall In New England at @sevenseastreetinn on Nantucket. Stroll through historic downtown or take in the sights from the extensive bike path system. https://t.co/C9eVgMKRk6 #bnbfinderdiamondcollection #bnbfinder #nantucket #bnb #bedandbreakfast #Massachusetts #fallcolors pic.twitter.com/AWGj6TLX6I
— bnbfinder (@BnBFinder) September 23, 2020
Otherwise, Tweets such as the below included hashtags for other cryptocurrencies even though it is not related.
BestChange — Collect free Satoshi BTC and learn e-currency exchange rates!
— Bitfor (@Bitfor2) October 23, 2020
Stable the faucet to collect the cryptocurrency.#BTC #USDT #Ethereum #EXCHANGE #dogecoin #money#ETH #NEO #LINK #FREE@cryptosfaucets @bestchangerushttps://t.co/WGgogbVjBQhttps://t.co/XWIeiYPCV6 pic.twitter.com/wTnOmBUogZ
An alternative to the above cursor search, you can try using snscrape to obtain the Tweet Ids of the period you required, and mine the data using Tweepy’s statuses_lookup:
tweet_ids = ['1309224717543510039', '1309071310107140099', '1309028231731965955']
statuses = api.statuses_lookup(tweet_ids, tweet_mode="extended")You can mine 100 Tweets in one go but you may also run into the below warning:
IOPub data rate exceeded. The notebook server will temporarily stop sending output to the client in order to avoid crashing it.
To overcome that, start your Jupyterlab or Jupyter notebook with the below configuration:
jupyter lab –NotebookApp.iopub_data_rate_limit=1.0e10
5. Tweet Sentiment
For my project, I’m using TextBlob to obtain the Twitter sentiment. In order to perform NLP (natural language processing) on the Tweets, I need to perform text processing on them so as to clean and prepare the data into a predictable and analyzable format.
Polarity without pre-processing
Let’s first see what is the sentiment of the above Tweet without performing any pre-processing.

We see the above Tweet has a polarity value of 0.5 which means it is a positive Tweet. Polarity is a float that ranges from -1.0 to 1.0. The tweet is said to be neutral if its polarity is 0.0 and negative if the value is less than 0.
Polarity with pre-processing
Let’s preprocess the same text to see if it affects the polarity drastically. We download the stopwords and wordnet from nltk.
import nltk
nltk.download("stopwords")
nltk.download("wordnet")
from nltk.corpus import stopwords
from nltk.stem import SnowballStemmer, WordNetLemmatizer
from nltk.tokenize import RegexpTokenizer
from textblob import TextBlob
stop_words = stopwords.words("english")
stemmer = SnowballStemmer("english", ignore_stopwords=True)
lemmatizer = WordNetLemmatizer()By using the Twitter posting above, let’s perform some pre-processing on its text:
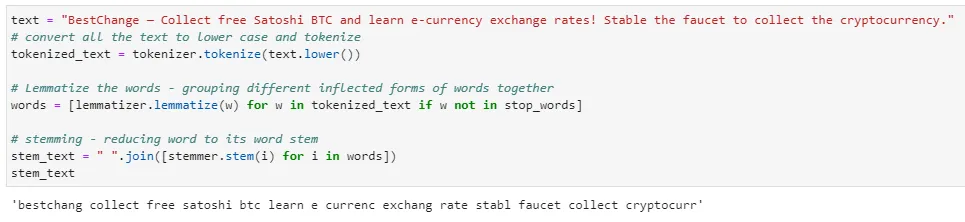

The resultant sentence is not linguistically correct. However, when we apply TextBlob on the text, we get a final sentiment polarity of 0.4. This value is lower than the one without pre-processing.
In any case, it is necessary to preprocess the text so that we have cleaner and standardized data.
Conclusion
80% of my time is spent gathering the data, cleaning it up, and deriving the Tweet sentiment. It’s a hair-pulling experience. You can access my notebooks on these links: mining Twitter and getting the Tweet sentiments. Hopefully, you will have a better experience than me.
Lookout for my next two articles on the easier task of mining the returns of the Cryptocurrencies and how I performed time-series analysis on these data to forecast the returns.