




Currency conversion is important. In an ever increasingly globalized world, businesses are more likely to record transactions in multiple currencies: a freelancer may charge according to the local currency of their latest project; a sales firm might send a team to potential clients in another country, and have to reimburse charges accrued in another currency.
Having a multi currency business adds a complication to fact finding and analysis. Even ignoring changing exchange rates based on transaction date, knowing the income or outflow of money is no longer as simple as adding up the charges. An amount column may not necessarily be enough information to know how much was spent–the currency column becomes an important input as well.
So, what do we do if we want to run analytics on our transactions? How do we keep the subtotals and totals accurate/true in our cube?
Read on, and check out the corresponding notebook in our GitHub notebook gallery.
Set Up
Consider the following simple example, where charges were incurred across multiple locations, in multiple currencies.
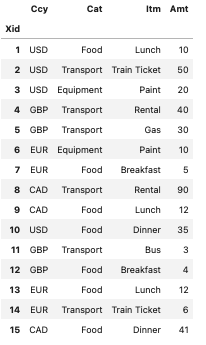
We created a cube using Atoti, in something called auto mode. This means Atoti will create hierarchies and measures based off the underlying datatypes. Let’s see what we have via a simple pivot table visualization.
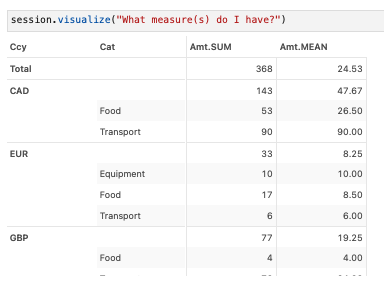
As this pivot table is laid out, with currency as the left most bucketing, the subtotals for the mean and sum amounts make sense–but the grand total does not. After all, what would 143 (CAD) + 33 (EUR) + 77 (GBP) + 115 (USD) = 368 even mean? These are not currencies with exchange rates of one.
One way to handle this is to hide the grand total row in our table.
But what if we wanted to compute these measures in a specific currency? How do we combine the information from our currency table with the transaction table?
Currency Conversion Rates
Let’s assume the base opperation for our business is in the United States, hence conducts its business in USD.
For this exploration, we’ll use a simple conversion dataframe.
usd_conv = session.read_pandas(
pd.DataFrame(
columns=["From", "To", "Rate"],
data=[
("USD", "USD", 1.0000),
("CAD", "USD", 0.7768),
("EUR", "USD", 1.1282),
("GBP", "USD", 1.3319),
],
),
table_name="ccy_conv",
keys=["From"],
)Let’s freshly create a measure for the Amt column.
We’ll use tt.value() here. Using the levels parameter, we can set up which level(s) we want to require for the measure to express a value. Since this amount only makes sense with its currency, I’ll set the currency level here.
m["Amt"] = tt.value(transactions["Amt"], levels=[l["Ccy"]])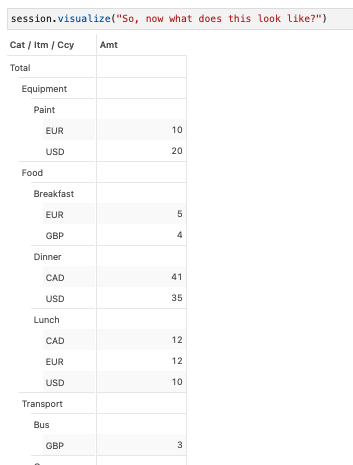
What about if we wanted to create a new measure which gives us the total USD cost of each of these transactions? For this, we would need to apply the currency conversion rate. Let’s first create a measure reading in the Rate data. Since our two tables are joined via their “Ccy” and “From” columns, respectively, we can simply multiply the two measures and aggregate. In fact, since all of this is in USD, having the totals also make sense, so we can aggregate them.
m["Rate"] = tt.value(usd_conv["Rate"])
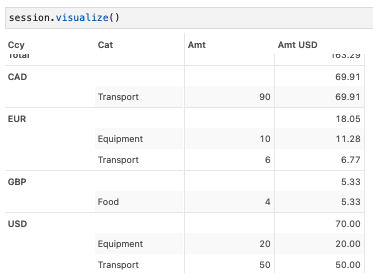
m["Amt USD"] = tt.agg.sum(m["Amt"] * m["Rate"], scope=tt.scope.origin(l["Cat"]))Now, if we check to see the amount vs their value in USD, we see we have the rate applied.
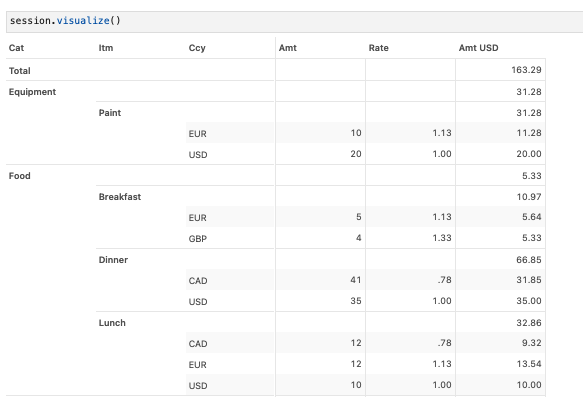
So, how do we clean up the measures with which we began? Afterall, we still see then in the widget editor. We can either hide or delete measures, as appropriate. Hiding measures make sense when the measure is used in a computation elsewhere. Since we created our measures from scratch, we can safely delete m[“Amt.SUM”] and m[“Amt.MEAN”].
del m["Amt.SUM"]
del m["Amt.MEAN"]A note about the newly creating Amt USD measure: it is still accurate regardless of the order of our hierarchies, allowing us to view the transaction costs from multiple perspectives.
We hope you enjoy this guide. Check out our other guides here.


