




Data classification gives visibility that uncovers fraud, rook spending or mismatched data
2021 is a year of harvesting for Susan Walsh – the fixer of dirty data!
- After three and a half years of working tirelessly, her business – The Classification Guru – has finally taken off.
- She’s done with her book: Between the Spreadsheets: Classifying and Fixing Dirty Data (pending publication – look out for it!).
- She’s a finalist at the British Data Awards for Data Leader of the Year.
https://www.linkedin.com/in/susanewalsh
Follow us in part one of this interview with Susan as we understand more about ‘dirty data’ and how the ‘classification guru’ ensures that data has its COAT on.
Huifang: Could you give some examples of dirty data?
Susan: If you want to put “dirty data” into context, I once cleansed 2.3 million rows in a database to reduce the duplications down to 1.3 million rows. There were lots of names that were either duplicates or near duplicates.
For example, on spend data classification, supplier names may come in different variations such as “I.B.M”, “IBM Inc”, “IBM Ltd”, “PWC” and “PricewaterhouseCoopers”.
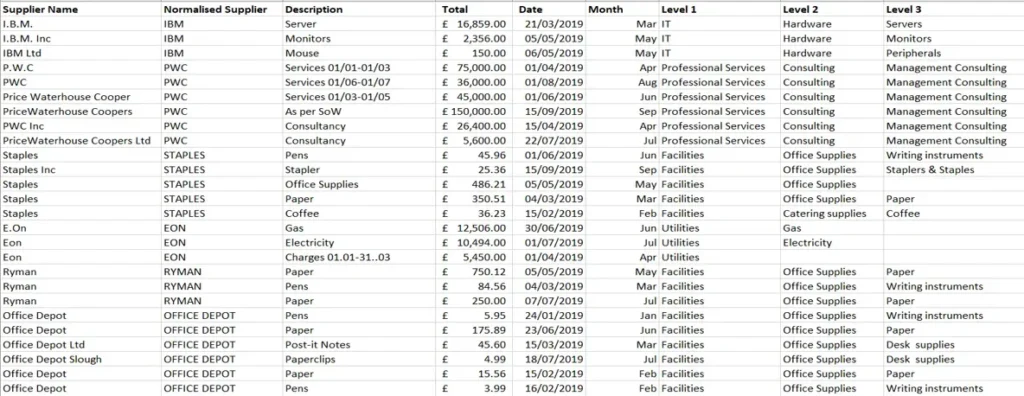
I normalized my client’s supply from 43,000 down to 34,000. Before that, they had no visibility of their spending with each supplier because they have five different versions of each one. If it was £100,000 on one supplier, it could look like £500,000 because there are different name classifications for the same supplier.
Classification gives visibility and changes the decision-making process. It flags out issues such as fraud, rook spending or mismatch accounts.
Huifang: What would be the biggest challenge to data classification?
Susan: Classification is really subjective, particularly with spend data classification. I might think it should be classified as ‘A’ while you might think it’s ‘B’, and we are both right. But we have to choose one option.
If there’s only one person working on it, your standards will be pretty consistent. It is hard to keep this consistency amongst a number of different people. You have to agree within your team on the kind of standards you need before you start.
In my opinion, this is when data needs to wear its COAT:
Consistent – in communication, work ethic and results.
Organised – to make sure your data is returned when agreed.
Accurate – so you can make better business decisions.
Trustworthy – so you know the decisions you make are correct.
Huifang: Data classification usually is part of a project design phase, performed by the project team. What makes you think there is a niche here? And why would companies be willing to outsource it?
Susan: The fact that I have a growing business shows that there is a need for this service. People are looking at the details a lot more now and they’ve realized the need for accurate data.
What I’m doing is not rocket science and companies can do it themselves. However, their staff may perform data clean up and classification once a year. I do it every single day. Hence, I do it more efficiently and accurately. Having come across so many different problems, I’ve gained valuable experience, helping me to fix problems faster than others.
I am not here to replace people within an organization. I am here to get the data up to the right level before handing it back to them and possibly training them to maintain their data. They are then responsible for maintaining it.
Huifang: In the grand scheme of the data pipeline, where does your service come in?
Susan: Honestly, I normally step in when something has gone wrong and clients can’t get what they need from the business. However, the best time for me to get involved would be at the very start.
I don’t do any analysis on the data. I am solely the fixer of the data.
My job is to take the data, clean it, classify it and hand it back to them.
Huifang: How do you convince companies to see data maintenance as an important investment?

Susan: As you’ve probably seen, I do a lot of videos and postings on LinkedIn to explain the need for data maintenance, the consequences of not having it, and the services I offer. So when people have a problem, they get in touch directly with me.
By posting on LinkedIn daily and regularly, talking about different data issues, people remember me. They know who to go to when they have these problems.
Huifang: You have always used procurement in your examples. Do you only work for this domain? Do you need to have an understanding of each business before you can fix their data?
Susan: I refer back to procurement because that’s where my background has been and that’s what I’ve done in the past. But I have worked with retailers such as a hardware DIY client.
As you start a project, you might have something that you don’t know how to classify on day one. However, you’ll probably see enough data patterns by day five to classify the things that you were stuck on from day one.
You learn as you go. Within a day of working with the data, you should be able to understand that well enough.
Huifang: Do you have any tips for individuals or businesses to help them identify data that is misclassified, part-classified or unclassified?
Susan: The most basic thing to do is to conduct a spot check on a dataset to see how it is classified. For instance, words such as “hotel” should be categorized as travel and words such as “taxi” could be categorized under employee expenses. If the classification is wrong, then there is a real problem with the details.
If you want to take it a level up, you could create a pivot table to identify the misclassified data. Let’s say you want to check if you have multiple descriptions against the product code, having the descriptions alongside the product code allows you to see where you might have multiple classifications against one product code.
You don’t need expensive software to create a pivot table, you can do it in Excel. If you need some higher-end software, there’s Tableau, Qlik or PowerBI which allows you to perform checks using visualizations.
(Huifang: There’s Atoti too! And it’s free 😉 )
Huifang: What are AI and RPA’s role in the data classification space?
Susan: RPA is great in that it’s more accurate than using humans and saves a lot of time. However, AI and machine learning are built on top of clean datasets. To get those clean datasets, you need people like me. You will also need a subject-matter expert to review the output from AI and machine learning.
As I mentioned earlier, classification is subjective, especially spend data classification. There’s often more than one right answer. AI will not be able to determine the uncertainty here, unlike humans, who will always be guided by rules that are defined and agreed upon before the start of the project.
Now that we are done with the technical expertise of Susan, follow us as we get down to her business and her new book in the next part of the interview.


